题目
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.' 匹配任意单个字符'*' 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例 1:
1
2
3
| 输入:s = "aa" p = "a"
输出:false
解释:"a" 无法匹配 "aa" 整个字符串。
|
示例 2:
1
2
3
| 输入:s = "aa" p = "a*"
输出:true
解释:因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
|
示例 3:
1
2
3
| 输入:s = "ab" p = ".*"
输出:true
解释:".*" 表示可匹配零个或多个('*')任意字符('.')。
|
示例 4:
1
2
3
| 输入:s = "aab" p = "c*a*b"
输出:true
解释:因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
|
示例 5:
1
2
| 输入:s = "mississippi" p = "mis*is*p*."
输出:false
|
提示:
0 <= s.length <= 200 <= p.length <= 30s 可能为空,且只包含从 a-z 的小写字母。p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。- 保证每次出现字符
* 时,前面都匹配到有效的字符
思考
这又是一个动态规划问题,但是为了方便理解,我们暂时不使用这个方法,我们从另一个角度考虑。
为了方便解释,我们设待匹配字符串为s,通配符串为p
回溯法
首先,我们降维问题,假设通配符只含有字母,那么只需要
进一步,我们加上通配符.,那么同样需要
1
| s[i] === p[i] || p[i] === '.'
|
再进一步,加入通配符*,考虑到*必须和前面一个字符结合使用,并且在匹配数量上,分两种情况:
- 不匹配任何字符(匹配数量为0),这种情况下直接将此通配组从p中移除
- 匹配一个或以上的字符(匹配数量>= 1),这种情况下,首先比较当前通配符P1的首个字符是否匹配s的首个字符,若匹配,匹配s的下一个字符,直到不匹配的情况出现,p切换到下一组通配符
1
2
3
4
|
if(p.length - p1 >= 2 && p[p1 + 1] === '*')
(s[s1] match p[p1 + 2]) || (s[s1] match p[p1] && (s[s1 + 1] match p[p1]))
|
结合以上,let’s solve the fking problem.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| var isMatch = function(s, p) {
if(!p) return !s;
let match = s && (s[0] === p[0] || p[0] === '.');
if(p.length >= 2 && p[1] === '*'){
return isMatch(s, p.slice(2)) || (match && isMatch(s.slice(1), p));
}else if(match){
return isMatch(s.slice(1), p.slice(1));
}else{
return false;
}
};
|
记忆化递归
回溯法思路清晰易懂,但是计算效率不尽人意,于是,我们想到记忆化递归,即尽可能将之前计算过的结果以字典的形式记录下来,即能节省递归深度,也可加快计算速度。
于是,我们改造下之前的算法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| var isMatch = function(s, p) {
let dict = new Array(s.length + 1).fill(0).map(x => new Array(p.length + 1).fill(0));
let matchFunc = function(s1, p1){
if(p1 >= p.length) return s1 >= s.length;
if(dict[s1][p1]) return dict[s1][p1] > 0;
let match = s1 < s.length && (s[s1] === p[p1] || p[p1] === '.');
if(p.length - p1 >= 2 && p[p1 + 1] === '*'){
let mc = matchFunc(s1, p1 + 2) || (match && matchFunc(s1 + 1, p1));
dict[s1][p1] = mc? 1: -1;
return mc;
}else if(match){
let mc = matchFunc(s1 + 1, p1 + 1);
dict[s1][p1] = mc? 1: -1;
return mc;
}else{
dict[s1][p1] = -1;
return false;
}
}
return matchFunc(0, 0);
};
|
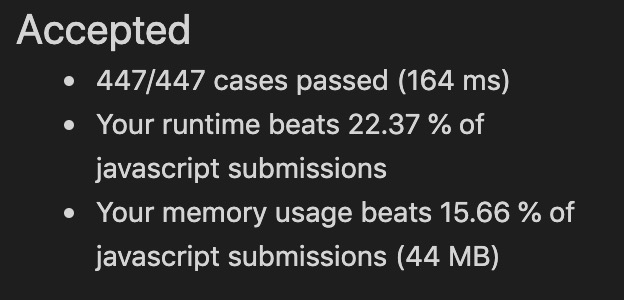
时间复杂度O(logn)短短几行植入,结果翻天覆地,令人满意(主要是大量减少了很多大深度递归,速度上升)。

动态规划
令人期待的动态规划解法来了,前前后后看了四五篇动态规划解法都感觉很晦涩,难以理解,然而有心人终不负,总算让我找到了一个相当丝滑的动态规划方法讲解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| 整理一下题意,对于字符串 p 而言,有三种字符:
普通字符:需要和 s 中同一位置的字符完全匹配
'.':能够匹配 s 中同一位置的任意字符
'*':不能够单独使用 '*',必须和前一个字符同时搭配使用,数据保证了 '*' 能够找到前面一个字符。能够匹配 s 中同一位置字符任意次。
所以本题关键是分析当出现 a* 这种字符时,是匹配 0 个 a、还是 1 个 a、还是 2 个 a ...
本题可以使用动态规划进行求解:
状态定义:f(i,j) 代表考虑 s 中以 i 为结尾的子串和 p 中的 j 为结尾的子串是否匹配。即最终我们要求的结果为 f[n][m] 。
状态转移:也就是我们要考虑 f(i,j) 如何求得,前面说到了 p 有三种字符,所以这里的状态转移也要分三种情况讨论:
p[j] 为普通字符:匹配的条件是前面的字符匹配,同时 s 中的第 i 个字符和 p 中的第 j 位相同。 即 f(i,j) = f(i - 1, j - 1) && s[i] == p[j] 。
p[j] 为 '.':匹配的条件是前面的字符匹配, s 中的第 i 个字符可以是任意字符。即 f(i,j) = f(i - 1, j - 1) && p[j] == '.'。
p[j] 为 '*':读得 p[j - 1] 的字符,例如为字符 a。 然后根据 a* 实际匹配 s 中 a 的个数是 0 个、1 个、2 个 ...
3.1. 当匹配为 0 个:f(i,j) = f(i, j - 2)
3.2. 当匹配为 1 个:f(i,j) = f(i - 1, j - 2) && (s[i] == p[j - 1] || p[j - 1] == '.')
3.3. 当匹配为 2 个:f(i,j) = f(i - 2, j - 2) && ((s[i] == p[j - 1] && s[i - 1] == p[j - 1]) || p[j] == '.')
作者:AC_OIer
链接:'https://leetcode-cn.com/problems/regular-expression-matching/solution/shua-chuan-lc-dong-tai-gui-hua-jie-fa-by-zn9w/'
来源:力扣(LeetCode)
|
Welcome Code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| var isMatch = function(s, p) {
const slength = s.length, plength = p.length;
s = ' ' + s;
p = ' ' + p;
let dp = new Array(slength + 1).fill(0).map(x => new Array(plength + 1).fill(false));
dp[0][0] = true;
for(let i = 0;i <= slength;i++){
for(let j = 1;j <= plength;j++){
if(j + 1 <= plength && p[j + 1] === '*'){
continue;
}
if(i - 1 >= 0 && p[j] !== '*'){
dp[i][j] = dp[i - 1][j - 1] && (s[i] === p[j] || p[j] === '.');
}else if(p[j] === '*'){
dp[i][j] = (j - 2 >= 0 && dp[i][j - 2]) || (i - 1 >= 0 && dp[i - 1][j] && (s[i] === p[j - 1] || p[j - 1] === '.'));
}
}
}
return dp[slength][plength];
};
|
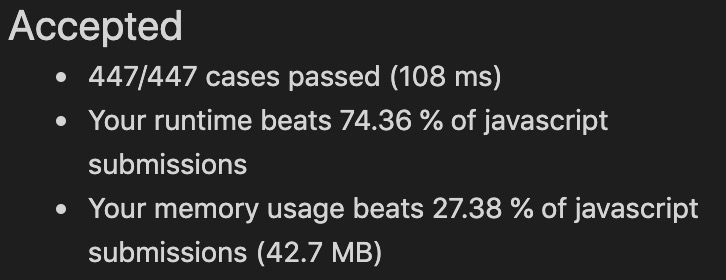
时间复杂度O(mn),令我意外的是并不如记忆化递归的效率高。
后记
吐槽一下自己刚开始的思路,完全偏离题目的考核内容,导致连续挂掉,(我的通过率 T。T )最佳的一次pass case 是 417/447,感觉努努力就能完成,然而捉襟见肘。所以一个正确的思路方向是有多重要~



